引き続きMySQL開発者のSven Sandbergのブログ MySQL Replication Ideas の翻訳版です。原文も確認してください。
Details of Re-execution and Empty Transactions / トランザクションの再実行と空のトランザクション
前回のブログポスト (オリジナル版 http://svenmysql.blogspot.co.uk/2012/10/failover-and-flexible-replication.html / 抄訳版 http://d.hatena.ne.jp/rkajiyama/20130301) では、GTIDがどのように生成され展開されていくかや、新しいレプリケーションプロトコル、フェールオーバーに役立つ要素などについて解説してきました。
今度は、GTIDがどのように機能するのかの詳細を解説します。特に、スレーブのスレッドが同じトランザクションを誤って繰り返し実行しない仕組みを確認します。また、mysqlbinlogでのメカニズムも確認します。トランザクションを空にするコンセプトと、どのように安全にトランザクションを抑制(実行せずにスキップする)かを確認しましょう。
The replication thread / レプリケーションスレッド
前回解説した通り、マスターはGTIDをイベントとして、トランザクションの内容の前にバイナリログに記録します。そして、スレーブのスレッドがGTIDを読むと、スレーブのサーバ変数gtid_nextをそのGTIDで変更します。例えば
スレーブのスレッドが読んだGTIDが4d8b564f-03f4-4975- 856a-0e65c3105328:4711の場合、以下のSQL文を発行します。
SET GTID_NEXT = 4d8b564f-03f4-4975-856a-0e65c3105328:4711;
これによって、スレーブはGTIDを自動生成するのではなく、4d8b564f-03f4-4975-856a-0e65c3105328:4711を利用します。
mysqlbinlog
上記のSQL文は、SUPER権限を持ったどのクライアントからでも実行可能です。
同じ仕組みはmysqlbinlogコマンドでも使われています。mysqlbinlogがGTIDのイベントを読み込むと、自動的にSET GTID_NEXT文を出力します。それによって、mysqlbinlogからの出力を実行するクライアントは、トランザクション内容だけではなくGTIDも同じまま実行が可能となります。
Transactions Must Only Execute Once / トランザクションは一度だけ実行されなければならない
もしGTID_NEXTで指定されたトランザクションが既に実行されていたらどうなるでしょうか?同じトランザクションが再度実行されてはなりません。まずデータの整合性がとれなくなる可能性がありますし、そもそも異なったトランザクションが同じGTIDを持つことはありえません。また、フェールオーバーの際に別のエラーを引き起こしかねません。
そのため、SET GTID_NEXTが実行されると、該当するトランザクションが既に実行されているか、@@GLOBAL.GTID_DONE @@GLOBAL.GTID_EXECUTEDからサーバがチェックします。
Empty Transactions – Making the Slave Skip Transactions / 空のトランザクション - スレーブでトランザクションをスキップする
既に実行されたトランザクションをサーバがスキップするのは、データを破壊してしまうような状況を避けるためだけではありません。GTIDを利用したフィルタリングや、データベース管理者が安全にトランザクションをスキップする、またはレプリケーションを特定の位置から安全にスタートすることを可能とします。(ここでいう安全とは、これらの操作を実行する分かりやすい方法で、次のフェールオーバーなどでデータを誤って破壊するような処理は実装していないことを指します)
下記の例をベースに説明を始めます:
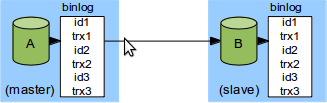
AがマスターでBがスレーブです。Aは3つのトランザクションを実行し、Bに全てが転送され適用されています。ここに新たなスレーブCをAに追加するというシナリオです。そしてトランザクションtrx1とtrx2はCで実行したくないとします。この2つのトランザクションをスキップする理由としては、Cは一部のテーブルのみを持つサブセットとする場合でtrx1とtrx2はCが持っていないテーブルに対するトランザクションであるケースや、またはtrx1はミスでtrx2で取り消し処理を行っているケース、またはこれらが非常に大きなトランザクションなので実行したくないケース、さらにはCにとって不要なケースなどが考えられます。
こういった場合には、Cはtrx3からトランザクションを開始したいと考えるでしょう。
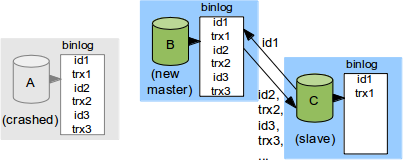
ここでフェールオーバーの際には何が起きるでしょうか?例えばAが停止してしまい、Bを新しいマスターに、CをBのスレーブにします。前回のブログポスト[]での説明の通り、新しいレプリケーションプロトコルでフェールオーバーが可能となっています。CがBに接続すると、CはIDの範囲をBに送り、その範囲に含まれないトランザクションをCに返します。この場合、Cはid3をBに送り、id1のtrx1とid2のtrx2を受け取り、Cでこれらのトランザクションがコミットされます。せっかくスキップしたはずのトランザクションがフェールオーバーによって実行されてしまいます。
この挙動はデータベースを壊してしまいかねない問題だけではありません。(C上でトランザクションが実行される順番が変わっています) エラーメッセージも出さずにデータを壊してしまい、フェールオーバーが発生するというそれだけでもデータベース管理者にとって問題のある状況を悪化させます。さらに、この問題のトランザクションは非常に古い可能性もあります。場合によっては何年も前のトランザクションで、データベース管理者自身もなぜスキップしたのか自体を思い出せずに、デバッグや問題解決を難しい物にしてしまいます。
ここでポイントになるのは、より安全な方法でこれらの状況を回避し、データベース管理者の悪夢を回避することができる点です。
GTID_DONEGTID_EXECUTEDに既に存在するGTIDをGTID_NEXTに設定すると、サーバはそのトランザクションをスキップすることを思い出してください。そこで、GTIDで指定されたトランザクションをスキップするため、まず始めに行うのは同じGTIDを再実行しないように設定することです。
例:
mysql> SET GTID_NEXT = “4d8b564f-03f4-4975-856a-0e65c3105328:4711”; mysql> COMMIT;
通常、COMMIT文単体では何も起こりません。しかし、GTID_NEXTにGTIDを設定した場合、サーバは空のトランザクションを記録し、バイナリログにはBEGINとCOMMITの間に何も書かれません。

これによって、該当のトランザクションは確実にスキップされます。もう同じトランザクションが再度実行されることはありません。
Empty Transactions and Failover / 空のトランザクションとフェールオーバー
先ほどの例にもどって、空のトランザクションを使ってtrx1とtrx2をスキップすると何が起こるかを見ていきましょう。CがスレーブとしてAに接続する前に、GTID id1とid2を空のトランザクションとしてCで実行します。
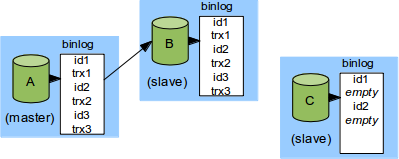
その後、新しいレプリケーションプロトコルを使ってCをAに接続します。CはGTID_DONE GTID_EXECUTEDをAに送ると、Aはそれ以外の全てをCに送ります。Cは"id1,id2"をAに送り、Aはid3のtrx3を返します。そしてレプリケーションが続きます。
ここまでは我々が必要としているが満たされています。Cはtrx1とtrx2をスキップしレプリケーションを開始しています。ただしid1とid2は存在しています。
では、フェールオーバーが起きるとどうなるでしょうか?Aが停止してしまい、Bを新しいマスターに、CをBのスレーブにします。Cは"id1-id3"をBに送り、Bはそれ以外のトランザクションを返します。trx1とtrx2はCには送られてきません。これらのGTIDは既にCで空のトランザクションで実行されているためです。
この例では、重要なポイントを強調しています。GTIDがサーバの状態も表しています。二つのサーバが同じデータを持っていても、それぞれのバイナリログに含まれるGTIDの範囲が異なる場合は、完全に同じとは見なされません。そして空のトランザクションなどを使うことで問題を起こさないようにできます。
Replication Filters and Empty Transactions / レプリケーションのフィルタリングと空のトランザクション
別のシナリオでは、空のトランザクションがレプリケーションのフィルタリングを行う上で重要な役割を担います。このフィルタリングを使って、マスターのデータベースの一部だけをスレーブに持たせる設計が可能です。もしスレーブのサーバを --replicated-ignore-db=mydatabase オプション付きで起動すると、スレーブはマスターから送られてくるバイナリログをチェックし、mydatabaseに関する処理は全てスキップします。
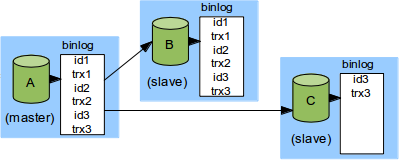
AがマスターでBとCが直接のスレーブだった場合を改めてみていますが、Cがmydatabaseに関する変更点をフィルタリングしているとします。
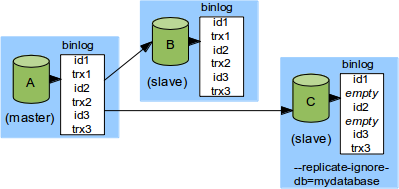
さらにtrx1とtrx2がmydatabaseに対する処理の場合、Cはそれらをスキップします。そしてCでは自動的に空のトランザクションをGTIDのid1とid2として記録します。
もしこの時点でAが停止すると、Bが新しいマスターとなり、CはBのスレーブとなります。このとき空のトランザクションid1とid2がCのGTID_EXECUTEDに記録されています。これによってCはBへの接続時にid1とid2をBに送るため、Bはtrx1とtrx2を再び送信することはありません。
これはパフォーマンスの観点から重要です。特にmydatabaseに対して実行されるトランザクションがmydatabaseそのものと同じぐらい大きい場合など、もしCで空のトランザクションを実行しないと、Bは大量のデータをCに転送する可能性があります。そしてフェールオーバーが既にスキップされたはずの(そして実行されることのない)大量のトランザクションを無駄に受け取ることとなります。